Transcriber¶
This utility is used to make a transcription of a voice or video recording, using the Whisper large language model from OpenAI. On top of this the utility uses WhisperX to add speaker diarization.
The app is present on UCloud with two different flavours: Tanscriber Default and Transcriber Batch.



Operating System:

Terminal:


Shell:



Editor:



Package Manager:






Programming Language:



Database:





Utility:


Extension:

Whisper:

WhisperX:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:


Programming Language:
Database:

Utility:
Extension:
Whisper:
WhisperX:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:



Programming Language:

Database:
Utility:
Extension:
Whisper:
WhisperX:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:




Programming Language:


Database:

Utility:

Extension:
Whisper:
WhisperX:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:
Database:

Utility:
Extension:
Whisper:

WhisperX:

Operating System:
Terminal:
Shell:
Editor:
Package Manager:

Programming Language:
Utility:
Extension:
Whisper:
WhisperX:
Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:
Utility:
Extension:
Whisper:
WhisperX:
Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:
Utility:
Extension:
Whisper:
WhisperX:
Operating System:
Terminal:
Shell:
Editor:
Package Manager:

Programming Language:
Utility:
Extension:
Whisper:
WhisperX:
Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:
Utility:
Extension:
Whisper:
WhisperX:

Operating System:
Terminal:
Shell:
Editor:
Package Manager:



Programming Language:


Utility:

Extension:
Whisper:

WhisperX:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:


Programming Language:

Utility:
Extension:
Whisper:
WhisperX:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:


Programming Language:


Utility:
Extension:
Whisper:

WhisperX:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:



Programming Language:


Utility:

Extension:
Whisper:

WhisperX:

Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:
Utility:
Extension:
Whisper:
WhisperX:

Operating System:
Terminal:
Shell:
Editor:
Package Manager:

Programming Language:
Utility:
Extension:
Whisper:

WhisperX:


Operating System:

Terminal:

Shell:



Editor:



Package Manager:




Programming Language:


Utility:

Extension:

Whisper:
WhisperX:
Transcriber Default¶
The Default version of the Transcriber app has a Graphical User Interface from which it is possible to upload files from the computer as well as to select files from a a UCloud directory.
Upload files from the computer¶
Input files can be uploaded from the user computer via a drag-n-drop window. Multiple files can be selected at once.
Uploaded files will be first stored in the /work/UPLOADS directory and then moved to the /work/COMPLETED directory
when the transcriptions are completed.
Use files from UCloud¶
In order to transcribe files from a UCloud directory, the folder needs to be mounted when starting the job, via the parameter Select folders to use.
Once the interface has been opened, the applicable media files will be shown under Use files from UCloud.
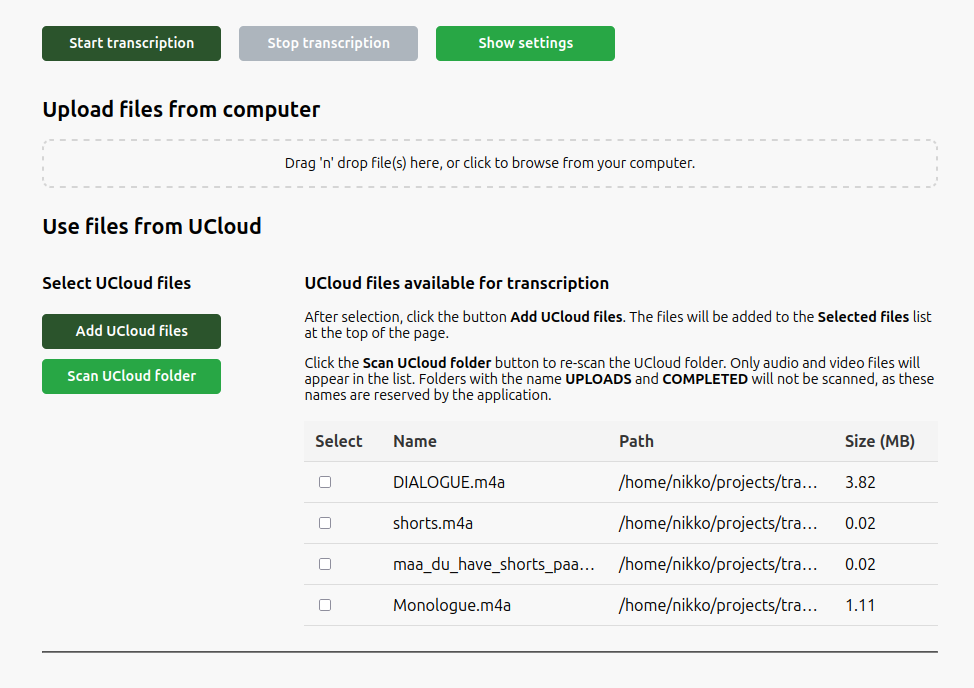
Audio and video present in the mounted directory, and in its subdirectories, will be listed as available for transcription. Select the files to be transcribed, and click the button Add UCloud files. The files will be added to the Selected files list at the top of the page.
It is possible to add files to the folder in UCloud after the transcriber interface has been started. In this case click the Scan UCloud folder to re-scan for applicable media files.
Note
The folder names UPLOADS and COMPLETED are reserved by the application, and folders with these names will not be scanned.
Transcription files¶
Transcribed files are saved in the /work/TRANSCRIPTIONS folder and
will be available on UCloud in the /Jobs/Transcriber/<job-id>/TRANSCRIPTIONS/, after job completion.
Transcription files can be downloaded while the job is running, from the app interface, both as single files and as a zip-file containing all transcriptions.
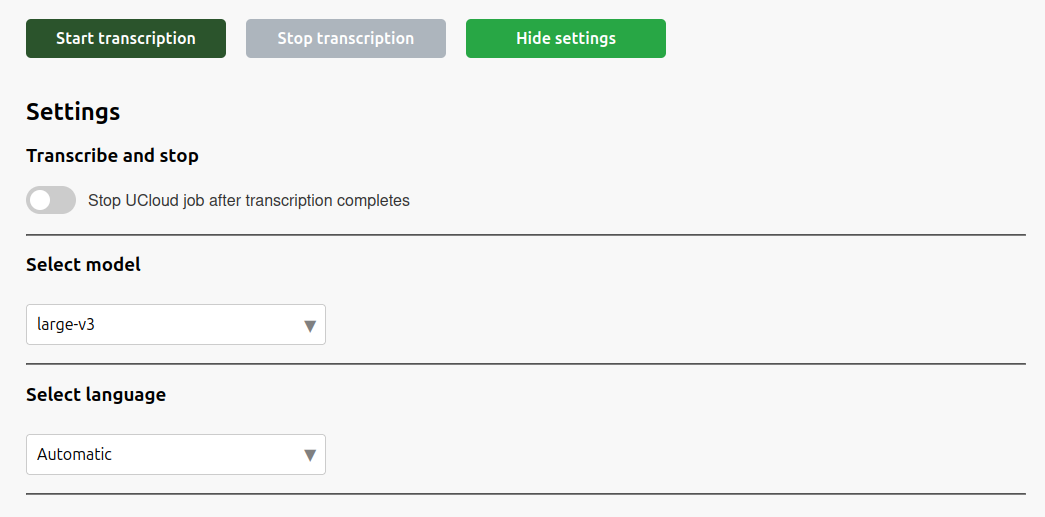
Settings¶
Transcription settings, as for example the transcription model and language to be used for the transcription, can be accessed by clicking on the Show settings button at the top of the page. By default, the model choice is large-v3 and the language choice is Automatic. The available models depends on the amount of memory in the machine type or GPU(s). Using a smaller model will speed up the transcription at the cost of lower accuracy.
Model name |
Required Memory |
Parameters |
|---|---|---|
whisper/base |
~1 GB |
74 M |
whisper/small |
~2 GB |
244 M |
whisper/medium |
~5 GB |
769 M |
whisper/large-v3 |
~10 GB |
1550 M |
whisper/large-v3-turbo |
~6 GB |
809 M |
nvidia/parakeet-tdt-0.6b-v3 |
~4 GB |
600 M |
The parakeet-tdt-0.6b-v3 model is designed for high throughput and fast transcription. The model automatically detects the input language. For a list of supported languages please refer to the huggingface documentation.
Note
The above table shows the minimum requirements for running the models. The memory requirements will increase when processing large audio files, so it will often be necessary to use a machine with additional memory.
The Transcribe and stop setting can be enabled to terminate the UCloud job once the transcription has finished. This will allow for more efficient use of CPU/GPU resources.
Transcriber Batch¶
The batch version of the transcriber application allows for setting a number of parameters when starting the job in order to run the transcription as a batch process. The job will then automatically stop when the transcription is completed.
App parameters¶
From the application's job submission page the user may specify a number of optional parameters, as needed:
Initialization:
Allows the user to run a Bash script (*.sh) with initialization code. This could be useful, for example, to pre-process audio files before transcription.Input file:
A single file which will be transcribed by Whisper. This optional parameter is suitable if the user only needs Whisper to transcribe one file in the job.Input directory:
The directory containing the file(s) which will be transcribed by Whisper. This optional parameter is suitable if the user needs Whisper to transcribe more than one file in the job. Output files are generated for each file in the 'Input directory'.Option
--output_dir:
If the user wants the output files to be saved somewhere else than the default output folder, the desired folder is specified here.Option
--output_format:
The file format of the output. See details above. The default is that all the output formats are generated and saved.Option
--model:
The model which Whisper will use for the transcription. The default islarge-v3, i.e., the largest, and most accurate model. The modellarge-v3-turbois faster to use, but when transcribing Danish the accuracy is not as good as when using thelarge-v3model. Using a smaller model will make the transcription process faster at the cost of accuracy.Option
--language:
Selecting a specific language forces Whisper to transcribe the input file(s) in that language. If no language is selected, Whisper tries to recognize the language.JupyterLab:
This option allows the job to start in an interactive mode with the JupyterLab interface started (by setting the parameter value totrue). This is useful if you want to run your own notebooks to call the whisper library. If the job is entered in this mode, the user can access the app terminal or web interface. The latter gives access to a JupyterLab workspace to run notebooks. The default setting isfalse.Archive password:
This will AES encrypt and password-protect the ZIP output archive. The user must specify a password for the archive as a text string.Option
--min_speakers:
If the number of speakers is known in advance this option can be used to set the minimum number of speakers. Using this configuration option may in some cases increase the accuracy of the speaker diarization.Option
--max_speakers:
If the number of speakers is known in advance this option can be used to set the maximum number of speakers. Using this configuration option may in some cases increase the accuracy of the speaker diarization.Option
--merge_speakers:
This option will enable merging of consecutive text entries from the same speaker into one entry in a set of additional output files postfixed with_merged.
Output files¶
By default the transcript files are saved in /Jobs/Transcriber/<job-id>/out. The user can select another directory using the corresponding app parameter --output_dir.
Input format¶
The app can process .mp3, .mp4, .m4a, .wav, .mpeg and .mpg files.
Output format¶
CSV:
Contains every parameter outputted from the Whisper model.DOTE:
DOTE Transcription software developed by the BigSoftVideo team at AAU.DOCX:
Office Open XML Document (Microsoft Word).JSON:
JavaScript Object Notation.SRT:
SubRip file format, widely adopted subtitle format.TSV:
Tab-separated value file contain start, end and text.TXT:
Pure text file with the transcriptionVTT:
Web Video Text Tracks format.ZIP:
Archive with all of the output files.
General Considerations¶
When using the Transcriber app, there are a few things to keep in mind:
Important: AI-generated transcriptions may not be 100% accurate. In some cases, Large Language Models (LLMs) may hallucinate, producing text that sounds confident but is not present in the original audio. We recommend reviewing the output for critical accuracy.
In general, larger models yield more accurate transcription results but also take longer to run. The user should therefore be sure to allocate enough time for the job, and/or extend the job lifetime if necessary.
Running Transcriber on a GPU node is considerably faster than running it on a CPU node. However, the app can only use one GPU at a time. Therefore, users should only allocate single-GPU machines (i.e.,
*-gpu-1machines) to their Transcriber jobs.When running Transcriber jobs on a CPU machine type, it is recommended to choose a machine with at least 16 cores and/or 64 GB of memory. Using less powerful machines may result in slow transcription and/or running out of memory.
Contents