Spark Cluster¶



Operating System:

Terminal:


Shell:



Editor:



Package Manager:






Programming Language:





Database:

Utility:


Extension:



Operating System:
Terminal:
Shell:
Editor:
Package Manager:



Programming Language:




Database:
Utility:

Extension:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:




Programming Language:




Database:
Utility:

Extension:


Operating System:

Terminal:

Shell:


Editor:



Package Manager:





Programming Language:





Database:

Utility:
Extension:



Operating System:
Shell:
Editor:
Package Manager:

Programming Language:




Database:

Operating System:

Shell:

Editor:



Package Manager:





Programming Language:



Database:


Operating System:
Shell:
Editor:
Package Manager:


Programming Language:


Database:


Operating System:

Shell:

Editor:

Package Manager:




Programming Language:



Database:


Operating System:
Shell:

Editor:
Package Manager:


Programming Language:


Database:

This app deploys a Spark standalone cluster.
Cluster Architecture¶
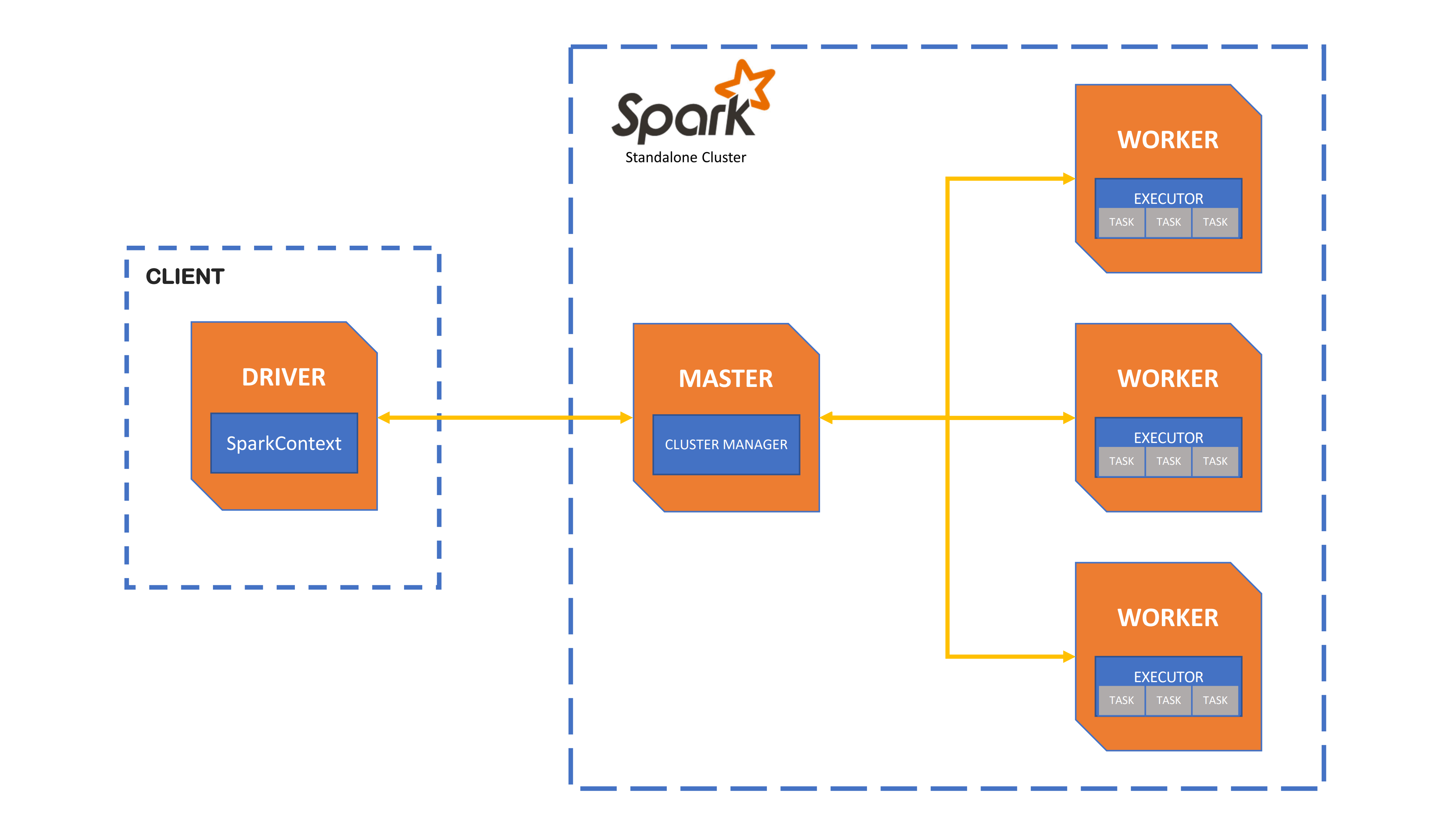
Apache Spark standalone cluster architecture in client mode
The cluster architecture consists of one master node (node1), acting as the cluster manager, and one or more worker nodes. By default, a worker process also runs on node1. The cluster configuration is defined by two mandatory parameters: Number of nodes and Machine type.
The master process receives application submissions and allocates worker resources (CPU cores and memory) accordingly. Worker processes then execute the tasks of each job. AApplications can be submitted either directly from the master node’s terminal or through another UCloud client application connected to node1, which also runs Apache Spark (see, e.g., JupyterLab). The Spark driver program creates the SparkContext and connects to the master node.
A standalone Spark cluster supports two deployment modes:
Client mode (default): The Spark driver runs in the same process as the client submitting the application (see figure above).
Cluster mode: The driver runs within one of the cluster’s worker processes. In this case, the client exits once it has submitted the application, without waiting for execution to complete.
The deployment mode is controlled by the property spark.submit.deployMode. A full list of configurable application properties for a Spark standalone cluster is available here.
Submit Applications¶
Applications can be submitted from the node1 terminal using spark-submit with the cluster’s master URL:
spark://node1:7077
Examples¶
Python (client mode, with event logging):
$ spark-submit \ --master spark://node1:7077 \ --deploy-mode client \ --conf spark.eventLog.enabled=true \ --conf spark.eventLog.dir=/work/spark_logs \ your_app.py --arg1 value1
Scala example (SparkPi from bundled examples):
$ spark-submit \ --master spark://node1:7077 \ --class org.apache.spark.examples.SparkPi \ "$SPARK_HOME"/examples/jars/spark-examples_*.jar 1000
Switch deploy mode¶
Add the following option to run in cluster mode:
--deploy-mode cluster
In cluster mode, the driver runs on a worker node and the client exits immediately after submission.
Resource configuration¶
Adjust these settings to match your cluster size and workload:
--executor-cores 4 --executor-memory 8g --total-executor-cores 32
Monitoring¶
Ongoing and completed Spark applications can be monitored through the web interfaces available on the cluster.
Spark UI¶
Each cluster node provides web interfaces for monitoring Spark components:
On
node1(master node):Spark Master UI – displays cluster-wide status and running applications.
Spark History UI – displays completed applications based on event logs.
Spark Worker UI – monitors the worker process running on the master node.
On all other worker nodes:
Spark Worker UI – monitors the worker process on the respective node.
For each application, the Spark UI provides:
A list of scheduler stages and tasks.
A summary of RDD sizes and memory usage.
Environmental information.
Information about running executors.
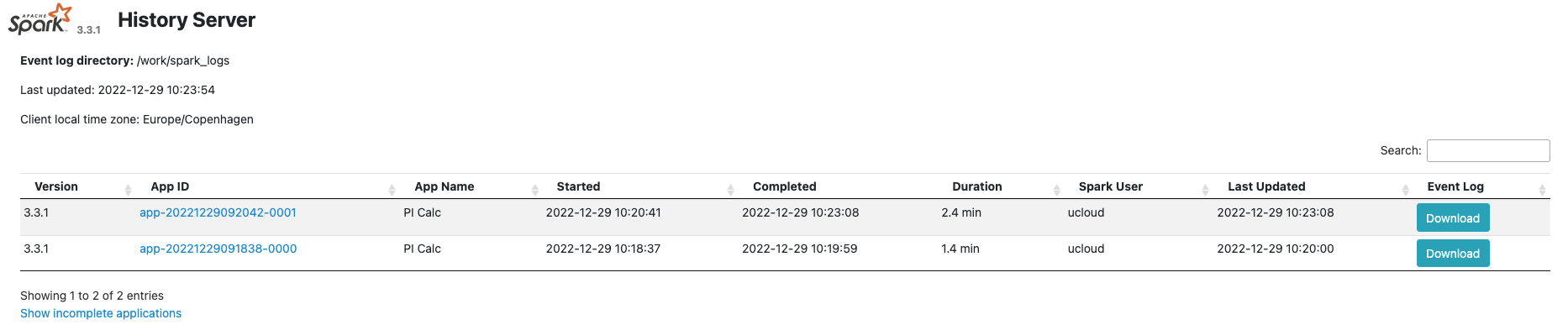
Spark history server¶
The Spark history logs are stored in /work/spark_logs, which is created by default when the job starts. A different directory can be specified using the parameter Spark history logs.
The Spark History UI is available exclusively from the node1 web interface.
Note
When the client runs in another UCloud app, the same logs folder must be mounted on both the cluster and the client applications.
Connect From Other Apps¶
Applications can also be submitted from other UCloud client apps (for example, JupyterLab and Airflow) by connecting them to the Spark Cluster job using Connect to other jobs.
Use the master URL
spark://node1:7077when creating yourSparkSessionor invokingspark-submit.Mount the same input folder on both the cluster and the client app to ensure consistent code and data paths.
To access the Spark history server, mount the same Spark history directory (
/work/spark_logsby default) on both the cluster and the client app.
Note
The client app must contain a compatible Spark installation and any additional packages required by the application.
Initialization¶
Additional packages may be installed on all the worker nodes by specifying the optional Initialization parameter.
For information on how to use this parameter, please refer to the Initialization: Bash Script, Initialization: Conda Packages, and Initialization: PyPI Packages section of the documentation.
Note
The same packages must also be installed on any client node connected to the Spark cluster.
Example¶
Initialization Bash script snippet to install a PyPI package on all nodes:
#!/usr/bin/env bash
set -euxo pipefail
pip install --no-cache-dir pyarrow==21.0.0
Run in Batch Mode¶
The Batch processing parameter enables Spark applications to be submitted through a Bash script executed on the master node.
Note
The job terminates once the script finishes executing, regardless of the script’s exit status.
Example¶
Minimal batch processing script:
#!/usr/bin/env bash
set -euxo pipefail
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=/work/spark_logs"
spark-submit \
--master spark://node1:7077 \
--deploy-mode client \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=/work/spark_logs \
/work/your_project/your_app.py
Contents