Polynote¶



Operating System:

Terminal:


Shell:



Editor:



Package Manager:





Programming Language:





Database:

Utility:


Extension:



Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:


Database:
Utility:
Extension:
Polynote is an open-source polyglot notebook that supports Scala and integrates seamlessly with Apache Spark. Its standout feature is multi-language interoperability, enabling data and variables to be shared across Scala, Python, SQL, and Vega cells within the same notebook. Polynote also supports the widely-used .ipynb notebook format, ensuring compatibility with other environments like Jupyter.
Initialization¶
For information on how to use the Initialization parameter, refer to the Initialization - Bash script section of the documentation.
Configuration Settings¶
Default setup¶
By default, the configuration file is located in /opt/polynote/config.yml. This file can be edited using the app's terminal interface. To apply any changes, the Polynote process must be stopped and restarted:
$ pkill -f "java -cp /opt/polynote/deps"
$ python3 /opt/polynote/polynote.py
Custom setup¶
A custom conf.yml file can be loaded before starting a job using the optional Configuration parameter.
The file must include the following lines to launch the app interface:
# ...
###############################################################################
# The host and port can be set by uncommenting and editing the following lines.
###############################################################################
listen:
host: 0.0.0.0
port: 8192
# ...
Note
Each notebook supports its own configuration, which can be modified dynamically without requiring a restart of Polynote. This functionality enables individualized settings tailored to specific projects or workflows.
Getting Started¶
Working with notebooks¶
Polynote utilizes .ipynb files, similar to Jupyter, but incorporates unique features:
Cell Execution Order: Polynote ensures that dependent cells are automatically updated when a parent cell changes, reducing the need to rerun entire sequences manually.
Multi-Language Cells: Unlike Jupyter, which requires separate kernels for different languages, Polynote allows each cell to be written in a different language while enabling seamless data sharing between cells.
Per-Notebook Configuration: Polynote provides per-notebook configuration for JVM and Python dependencies, Spark settings, and kernel options. This feature facilitates organized environments and ensures changes are isolated to specific notebooks.
Managing dependences¶
JVM dependencies are specified in GAV notation and resolved using Coursier.
Python dependencies are handled through
pipand can be listed in a.txtfile for automatic caching by Polynote.
For more information about the configuration options, refer to Polynote's Notebook configuration documentation.
Using multiple languages¶
Polynote allows value sharing across cells written in different languages. Examples provided in the app include:
A DataFrame defined in a Scala cell being used in a Python cell.
Sharing primitive data types (e.g., strings, integers) and structures (e.g., arrays, DataFrames) effortlessly, while complex objects may require serialization.
Further information is available in the multi-Language documentation.
Using Spark with Polynote¶
Polynote is deeply integrated with Apache Spark, making it well-suited for distributed data processing and big data workflows. By default, the app comes with Spark already installed, meaning you can immediately start running Spark applications locally. For larger datasets, Polynote also supports running applications in cluster mode.
Once configured, Spark can be used directly in a Python or Scala cell like so:
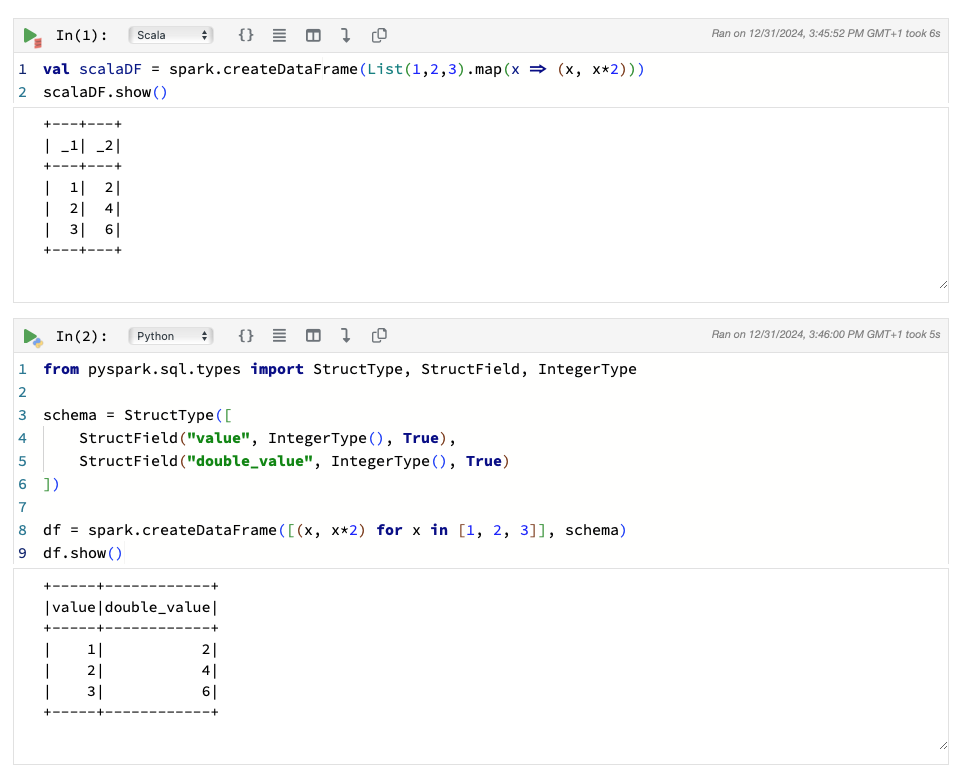
For more information on Spark in Polynote, refer to the official documentation.
Note
Polynote internally creates and manages the SparkSession, making it accessible across all cells within a notebook. The spark variable can be used to access the SparkSession locally in both Python and Scala cells.
The following subsections show an example of how to configure and run Spark jobs from a Polynote notebook.
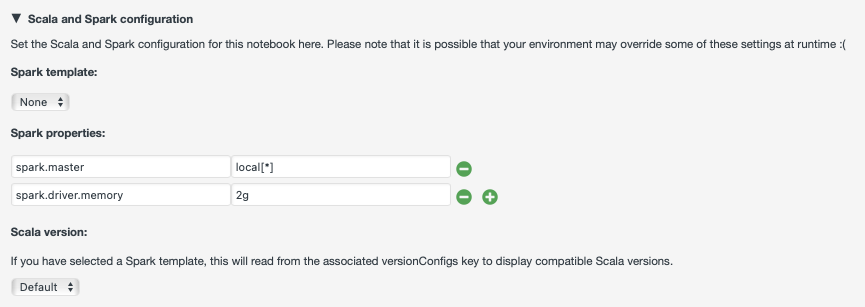
Local deployment¶
For smaller datasets, Spark applications written in Scala can be executed in local mode using resources allocated to the Polynote app. PySpark is also supported in local mode. To enable Spark in a notebook, ensure at least one Spark property is set in the configuration. An example configuration is shown below:
Cluster deployment¶
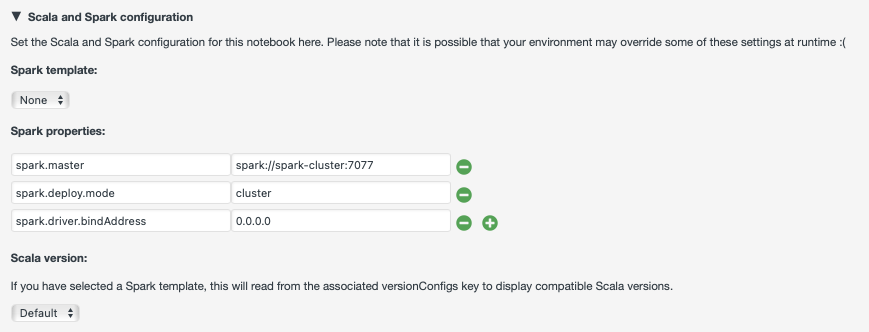
For larger datasets, Spark applications written in Scala can be submitted to a Spark standalone cluster, enabling the distribution of data processing tasks across multiple nodes. To achieve this, the Polynote app must connect to a Spark cluster instance by using the optional parameter Connect to other jobs, as demonstrated in the following example:

The Job entry is used to specify the job ID of the pre-created Spark cluster instance. Additionally, the Hostname parameter is used to define the URL of the master node in Polynote's Spark configuration. By default, the master node listens on port 7077.
Note
PySpark is not supported in cluster mode.
Spark application example¶
Following the JupyterLab's example, which is written in Python, the equivalent code in Scala for use in a Polynote notebook is as follows:
import scala.util.Random
// Define partitions and total points for PI calculation
val partitions = 567
val pointsPerPartition = 10000000
val totalPoints = pointsPerPartition * partitions
// Function to calculate if a point is inside the unit circle
def isInsideCircle(dummy: Int): Int = {
val x = Random.nextDouble()
val y = Random.nextDouble()
if (x * x + y * y <= 1) 1 else 0
}
// Parallelize the points across partitions and calculate Pi
val count = spark.sparkContext
.parallelize(1 to totalPoints, partitions)
.map(isInsideCircle)
.reduce(_ + _)
val pi = 4.0 * count / totalPoints
println(f"Pi is roughly $pi%.6f")
This code operates independently of the deployment mode:
Local Mode: Fully supports execution. Both PySpark and Scala environments are functional. Refer to the local deployment configuration.
Cluster Mode: Only Scala is supported for execution. Refer to the cluster deployment configuration.
Custom Settings: Add additional Spark properties by selecting the
+button in the notebook’s configuration interface.
Contents