Querybook¶



Operating System:

Terminal:


Shell:



Editor:



Package Manager:




Programming Language:


Database:




Operating System:

Terminal:

Shell:



Editor:



Package Manager:



Programming Language:


Database:




Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:
Database:


Operating System:
Terminal:
Shell:
Editor:
Package Manager:
Programming Language:
Database:



Operating System:

Terminal:
Shell:
Editor:
Package Manager:
Programming Language:


Database:



Operating System:

Terminal:
Shell:
Editor:
Package Manager:
Programming Language:

Database:


Querybook is an advance big data IDE discovering, creating, and sharing data analyses, queries, and tables via a notebook interface.
For more information, check here.
Start Querybook App¶
When starting the application on UCloud, one needs to select Signup and enter the required information. By default, this user is the app Administrator.
Administrators have all possible rights, including granting or revoking rights to other users and editing other users’ notebooks and dashboards. Custom permissions can be created through the Querybook interface.
Note
All users are registered in the server with an email address. However, there is no email server configured in the backend. Therefore, it is not possible to send emails to the users from the app web interface.
Connect to Databases¶
PostgreSQL database¶
The application starts a PostgreSQL database server.
The PostgreSQL database directory, named postgresql, is created by default in /work. After job completion, the database is accessible in the Jobs/Querybook/$JOB_ID directory on UCloud.
By default the PostgreSQL username is ucloud, the password is ucloud, and the name of the accessible database is also ucloud.
It is also possible to select a pre-existing PostgresSQL database by importing the corresponding directory using the Existing PostgreSQL database optional parameter, which also initializes the $PGDATA_DIR environment variable. If not corresponding to the default values, database name and login credentials must also be specified using the corresponding optional parameters.
To create a new PostgresSQL user and password and/or choose the name for a new PostgreSQL database, one can use the app terminal interface, e.g.:
$ psql -c "create user $user with encrypted password '$pass';"
$ psql -c "grant all privileges on database $postgres_db to $user;"
The general form of the PostgresSQL database connection string is:
postgresql+psycopg2://{username}:{password}@0.0.0.0:5432/{database}
The following video shows how to connect to the PostgreSQL database from the Querybook interface and associate the database to an environment.
Other query engines¶
It is possible to use different query engines.
The necessary packages to connect to the chosen database can be installed through the Initialization parameter, via a Bash script. Likewise the associated service can be started within the script. In this case it is necessary to specify the SQLAlchemy connection string to the database via the Connection string optional parameter (see, e.g., here for the string format).
Celery – Distributed Task Queue¶
Celery is an open source asynchronous task queue system which is based on distributed message passing, focusing on operations in real time.
Celery by default uses multiprocessing to perform concurrent task execution. The number of worker processes/threads can be changed using the worker concurrency parameter and, if not set, it defaults to the number of available CPUs.
uWSGI Settings¶
Several parameters, including the worker class, and the number of workers and threads, can be tuned by modifying the /opt/querybook/uwsgi.ini file, see here for details.
In order to use the customized version, the user must copy the new uwsgi.ini file in the /opt/querybook directory and overwrite the default configuration. This operation can be done with a Bash script through the Initialization optional parameter.
Share and Collaborate¶
Querybook allows users live query collaborations.
The figure below shows an example of how to share a notebook.
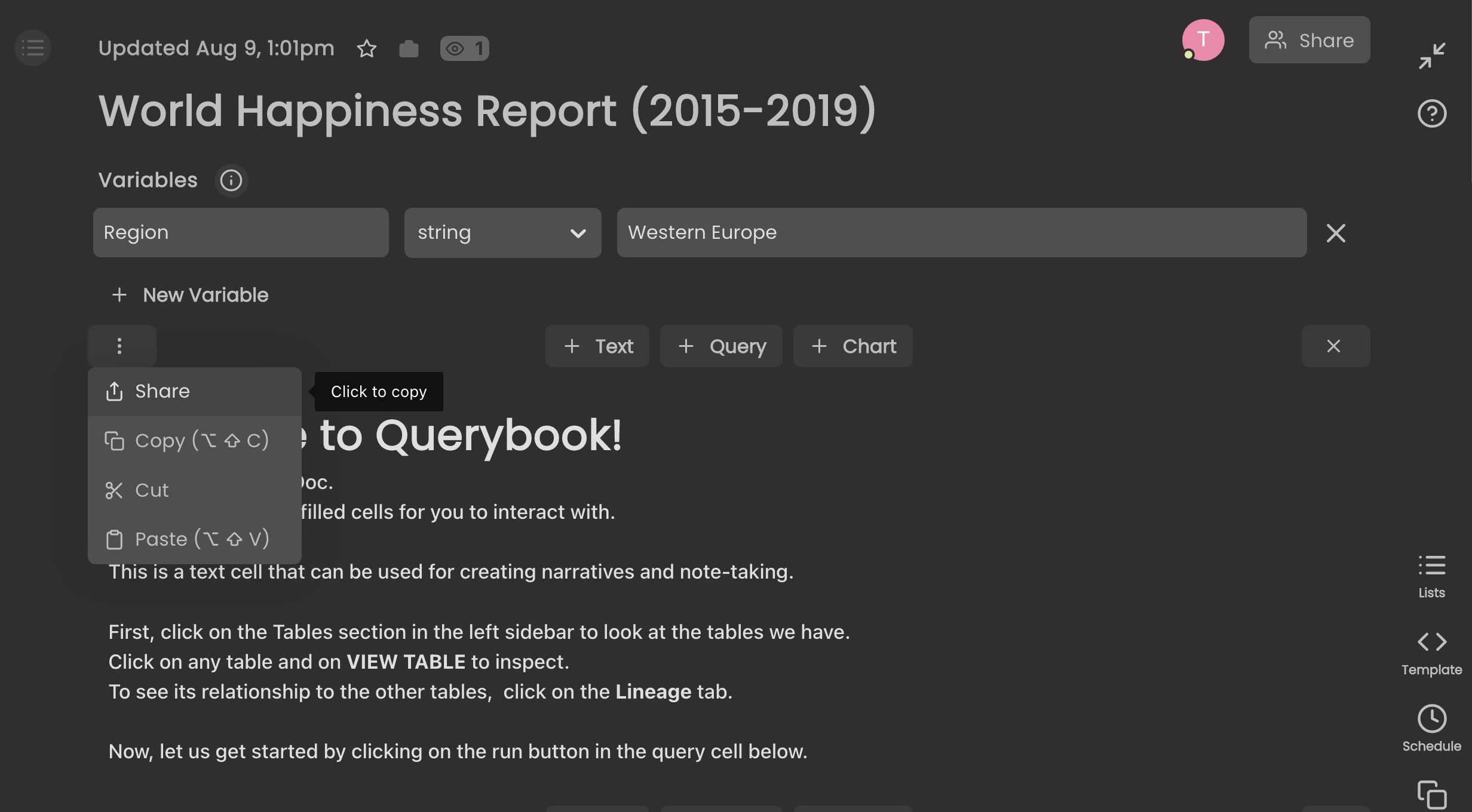
Collaborators can sign up and request edit permissions.
Note
The URL can be shared with collaborators only if the app is deployed with a public link.
AI Assistant¶
The AI Assistant package dependencies are included in the image. For details on the necessary steps in order to enable the AI assistant plugin see here.
Contents