Airflow Connections: Integration with Spark¶
Apart from executing tasks locally, like seen in the Airflow Basics documentation, Airflow can orchestrate tasks across distributed workers.
In the context of Airflow, a worker is a node capable of executing tasks delegated by the Airflow scheduler. Therefore, in addition to running the scheduler and web server, the Airflow job instance itself acts as a worker.
Airflow communicates with these workers through various mechanisms. In this use case the focus is on connections.
Connections in Airflow are predefined sets of parameters or credentials that facilitate seamless integrations with external systems. They can be managed via both the CLI and the UI, and like many components of Airflow, connections are customizable.
This use case will explain how Airflow integrates with a Spark Cluster by using these connections, and how to set up the jobs in UCloud.
Setup¶
In order to guarantee a proper set up of the connections, follow the steps:
Start a worker node job: The only requirement for Airflow to be able to send tasks to workers is that the worker has access to Airflow's DAG folder. To do this, generally, you should add your
AIRFLOW_HOMEdirectory to the parameters of the job. For a Spark cluster, include theAIRFLOW_HOMEdirectory in the Input folder parameter to ensure all nodes in the cluster have access to the DAGs.Start an Airflow job: To connect to the worker node, Airflow must have the correct provider installed. For Spark, the provider is installed by default. However, if other providers are needed, you can install them by adding the following to your initialization file (
.sh):#!/bin/bash pip install "apache-airflow==<airflow-version> <provider>==<version> # for example: pip install "apache-airflow==2.10.0" apache-airflow-providers-google==10.1.0
Lastly, in Airflow's job parameters, connect the worker job(s).
Important
It is important to maintain the same hostname of connected jobs across runs, since the connection will make use of the host name will be permanently stored in Airflow's metadata database.
Note
When importing parameters from a previous run, pay attention to the worker node's job ID in the Airflow job parameters. If the ID is of an older instance that is no longer running, the connection will fail and the Airflow instance will have to be restarted with the correct parameters.
Create the connection: This step is only needed once as long as Airflow metadata database remains the same. To create the connection, open the terminal window from the Airflow job, and execute the following command:
$ airflow connections add <connection-id> \ --conn-type 'spark' \ --conn-host 'spark://<your-spark-host-id>' \ --conn-port '7077'
Alternatively, the connection can be created via the web server UI, under Admin > Connections > Add connection.
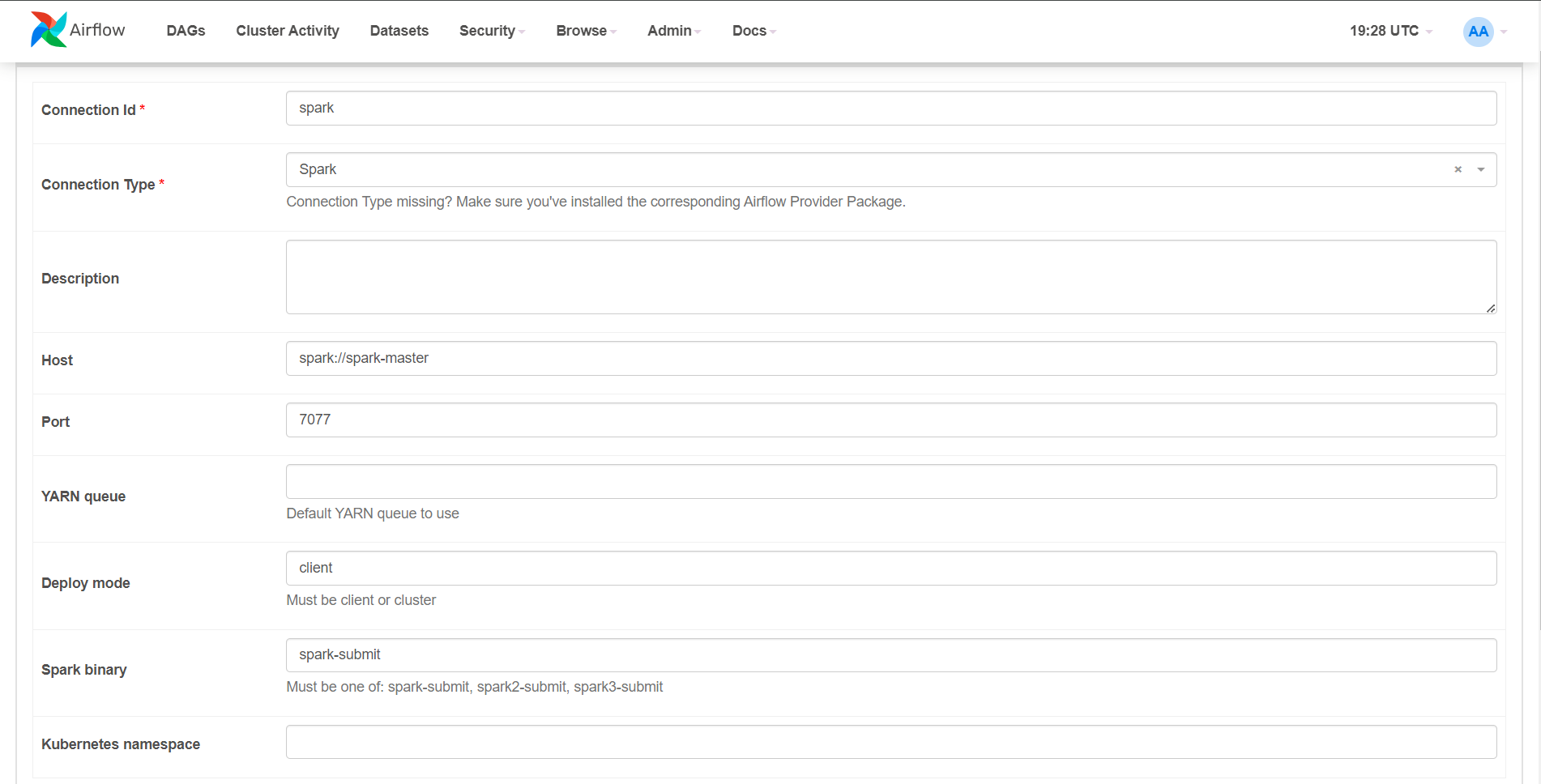
Fill in the different fields with the following information (with a connection ID of your choice and the host ID specified in the parameters of the Airflow job).
Spark Operators¶
The Spark provider in Apache Airflow installs a set of operators designed to manage workflows that involve Spark:
SparkSubmitOperator: Launches applications on a Spark server using thespark-submitscript. It is the most direct way to submit Spark jobs from a task, and supports configuration of various Spark parameters such as additional JARs, files, or packages, executor memory, driver memory or number of executors. Out of the three, this is the most general and flexible operator.spark_submit_task = SparkSubmitOperator( task_id='spark_submit_task', application='/path/to/your/spark_job.py', # Path to the Python or Jar file containing the Spark job conn_id='spark_connection_id', jars='/path/to/jar', # Extra jars files='/path/to/file', # Extra files executor_cores=2, executor_memory='2g', num_executors=2, name='airflow-spark', dag=dag, )
Note
All referenced files (application, jars, files) must also be accessible to the Spark cluster. Since the input folder for the Spark Cluster is set to
AIRFLOW_HOME(which already gives access to the DAGs), it is recommended to place these extra files (if they are being stored in UCloud) in theAIRFLOW_HOMEdirectory as well.SparkJDBCOperator: Performs data transfers to/from JDBC-based databases. Apart from configuring the Spark connection, it also requires a JDBC connection. The intended use case for this operator is for Java-based Spark jobs that involve extensive interactions with JDBC databases.SparkSQlOperator: Executes SQL queries on Spark Hive usingspark-sql. This operator does not need a Spark connection configured and can run the queries directly within a task. For this, the Spark master URL and the database have to be specified in the task's parameters.
Example pipeline using SparkSubmitOperator¶
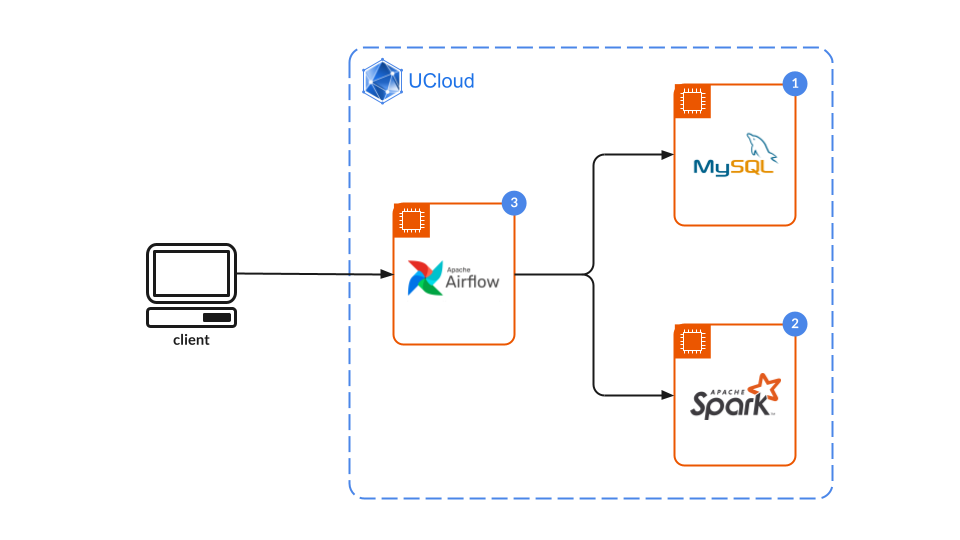
The following example is closely related to the ETL_Example in Airflow Basics documentation and makes use of the same MySQL Database and connection.
Additionally, the directories spark_logs/, jobs/, and data/ folders must exist in the AIRFLOW_HOME directory to run this example. Start by creating these directories, if they do not exist already.
Inside of jobs/, the following spark.py must also be created:
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName('TransformData').getOrCreate()
input_path = '/work/Airflow/data/iris.csv'
output_path = '/work/Airflow/data/transformed_iris' # Output folder
df = spark.read.csv(input_path, header=True, inferSchema=True)
columns_to_drop = ['sepal_width', 'id']
df_transformed = df.drop(*columns_to_drop)
df_transformed.write.csv(output_path, header=True, mode='overwrite') # Individually saves all workers' output into csv files
Add the following python script to the dags/ folder:
from airflow import DAG
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
from airflow.hooks.mysql_hook import MySqlHook
import pandas as pd
from datetime import datetime
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1),
}
def query_mysql():
hook = MySqlHook(mysql_conn_id='mysql')
connection = hook.get_conn()
cursor = connection.cursor()
cursor.execute('SELECT * FROM iris WHERE species = "setosa";')
result = cursor.fetchall()
cursor.close()
connection.close()
df = pd.DataFrame(data=result, columns=["id","sepal_length","sepal_width","petal_length","petal_width","species"])
df.to_csv('/work/Airflow/data/iris.csv', index=False) # # Change /work/Airflow to your $AIRFLOW_HOME
with DAG('ETL_Spark_example', default_args=default_args, schedule_interval=None, tags=["ucloud_example"]) as dag:
extract_data_and_save_to_csv = PythonOperator(
task_id='extract_data_and_save_to_csv',
python_callable=query_mysql,
)
process = SparkSubmitOperator(
task_id='spark_job',
application='/work/Airflow/jobs/spark.py', # Change /work/Airflow to your $AIRFLOW_HOME
conn_id='spark',
conf={
"spark.eventLog.enabled": True,
"spark.eventLog.dir": "/work/Airflow/spark_logs", # Change /work/Airflow to your $AIRFLOW_HOME
"spark.history.fs.logDirectory": "/work/Airflow/spark_logs", # Change /work/Airflow to your $AIRFLOW_HOME
},
)
extract_data_and_save_to_csv >> process
To run the DAG, press the Play button in the UI, or execute the following command:
$ airflow dags trigger ETL_Spark_example
This example showcases a pipeline that extracts information from a MySQL database and processes it using Spark. The tasks are very simple:
extract_data_and_save_to_csv: Queries part of the Iris dataset from a MySQL database and saves it as a CSV file (iris.csv) in the/work/Airflow/data/directory.process: UsingSparkSubmitOperator, submits a Spark job (spark.py) located in the/work/Airflow/jobs/directory.
The Spark job reads iris.csv and splits the work between the workers in order to perform the specified data transformation (i.e., removing the columns sepal_width and id). The output of every worker is saved in the folder /work/Airflow/data/transformed_iris.
Start Spark with BashOperator¶
While Airflow offers specialized operators like SparkSubmitOperator for managing Spark jobs, it is also possible to also submit Spark jobs using a BashOperator. This approach allows the user to execute Spark jobs like one would do from a terminal, without needing to set up an Airflow connection (connecting the jobs is still necessary). An example of the use of BashOperator is the following:
spark_submit_bash_task = BashOperator(
task_id='spark_submit_bash',
bash_command='python /work/Airflow/jobs/spark.py',
dag=dag,
)
When using BashOperator to submit Spark jobs, the user must ensure all Spark configurations (connection to the Spark master, dependencies, extra files, and spark-submit parameters, for instance) are appropriately set inside the Python script. An example of a Spark script for this case can be found here.
Contents
SparkSubmitOperatorBashOperator